kafka入门
是什么
是由Apache开源,使用scala和java编写的一个分布式的基于发布/订阅模式的消息队列。
kafka使用了长轮询的方式来拉取消息,避免了在消费者端性能瓶颈问题,采用拉取消息的方式可以根据消费者的性能灵活消费消息,但此方式也有缺点,即消费者需要每隔一段时间进行拉取,如果时间过长,会出现消息延迟,如果时间过短进行频繁请求对kafka的压力也会过大。
几种常见的消息队列区别
| 特性 | ActiveMQ | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|---|
| 所属社区/公司 | Apache | Mozilla Public License | Apache | Apache/Ali |
| 成熟度 | 成熟 | 成熟 | 成熟 | 比较成熟 |
| 生产者-消费者模式 | 支持 | 支持 | 支持 | 支持 |
| 发布-订阅 | 支持 | 支持 | 支持 | 支持 |
| API完备性 | 高 | 高 | 高 | 低(静态配置) |
| 多语言支持 | 支持JAVA优先 | 语言无关 | 支持,JAVA优先 | 支持 |
| 单机呑吐量 | 万级(最差) | 万级 | 十万级 | 十万级(最高) |
| 消息延迟 | - | 微秒级 | 毫秒级 | - |
| 可用性 | 高(主从) | 高(主从) | 非常高(分布式) | 高 |
| 消息丢失 | - | 低 | 理论上不会丢失 | - |
| 消息重复 | - | 可控制 | 理论上会有重复 | - |
| 事务 | 支持 | 不支持 | 支持 | 支持 |
| 文档的完备性 | 高 | 高 | 高 | 中 |
| 首次部署难度 | - | 低 | 中 | 高 |
消息队列解决了什么问题(好处)
异步操作
假如一个服务调用另一个服务时间比较长时,可以使用消息队列进行异步处理,将请求参数发送至消息队列,再由服务获取消息队列中的数据进行慢慢消化。(一些没有强制关联的操作,也可以使用消息队列来加快响应速度,比如注册时的发送邮箱确认,注册后可以立即给出响应,发邮件的操作可以交给消息队列去做)。
解耦合
一个模块的处理需要强依赖另一个模块时,假如被依赖的模块出现故障,自然也会影响调用模块的运行,引入消息队列后,可以先将请求参数保存至消息队列中,被依赖模块从消息队列中获取请求参数。
流量削峰
比如秒杀下订单时会有大量用户在同一时间请求服务,可能会导致服务因此宕机,可以引入消息队列,对请求进行排队和限制,然后慢慢消化。
为什么选择kafka
一些大型网站需要通过日志分析用户的使用行为,日志数据通常都是大量的,而kafka的优点则是高吞吐量、高性能并且支持分布式,可以从我们G01系统中看到有许多统计的地方,这些数据也大多是用户日常使用的行为日志,通过使用kafka结合es来对这些日志数据进行分析统计,可以更直观的感受用户的使用习惯和系统的功能性。
推送VS拉取
推送(push)
push模式下消息的实时性更高,对于消费者使用来说更简单,反正有消息来了就会推过来。 但push模式很难适应消费速率不同的消费者,因为消息发送速率是由服务端决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成消费者来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。
拉取(pull)
pull模式主动权就在消费者身上了,消费者可以根据自身的情况来发起拉取消息的请求。假设当前消费者觉得自己消费不过来了,它可以根据一定的策略停止拉取,或者间隔拉取都行。 消息延迟,因为是消费者是主动拉取消息,它并不知道消息的存在与否,于是只能不停的去拉取,但又不能很频繁,太频繁对服务端的压力也很大。
Kafka的解决方案
首先Kafka采用了pull拉取消息的模式,消费者采用长轮询的方式去服务端拉取消息时定义了一个超时时间,如果有马上返回消息,没有的话消费者等着直到超时,然后再次发起拉消息的请求。
kafka的名词解释
producer: 生产者,生产者生产消息数据发送至broker。
consumer: 消费者,消费者从broker中读取数据做处理。
broker: 已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker),反言之每一个Broker就是一个Kafka的实例。
topic: 是kafka下消息的类别,每一类消息都可以称为一个topic,是逻辑上的概念,用来区分、隔离不同的消息,开发时大多只需要关注消息存到了哪个topic,需要从哪个topic中取数据即可。
partition: 分区,为了负载均衡,将同一个Topic分为多个分区分别存储在集群中不同的broker上,每一个Topic可以有多个分区,但一个分区只属于一个主题,同一个主题中不同分区之间的数据不一样。这样做的好处是当存储不足时可以通过增加分区实现横向扩展。分区数也不是越多越好,配置为broker节点的整数倍即可。
offset: 写入topic的消息会被平均分配到每一个分区,到达分区后会落实到一个文件中,消息在文件的位置就是offset(偏移量),是消息在分区中的唯一标识。(开发时可以灵活的使用该属性进行消息消费,可以指定消费者从指定的offset开始消费)
replicas:分区的副本,保障了分区的高可用, 每个分区在每个broker上最多只有一个副本。
Leader: 分区中的一个角色, Producer 和 Consumer 只与 Leader 交互;
Follower: 分区中的一个角色,从 Leader 中复制数据,作为它的副本,同时一旦某 Leader 挂掉,便会从它的所有 Follower 中选举出一个新的 Leader 继续提供服务;
Zookeeper在Kafka中的作用: Kafka集群之间并不直接联系,而是将各自节点信息注册到Zookeeper,由ZK进行统一管理。
小结
多个broker组成一个Kafka集群,broker之间通过Zookeeper进行通讯,一个broker中可以有多个topic,生产者可以将消息发送至topic的不同分区中,同一个topic的不同分区内的消息不一样,每个分区可以有最多N(取决与broker的数量)个副本保存在不同的broker中。
消费者从订阅的topic中拉取消息,可以通过增加消费者形成消费者组来提高消费者的消费速度。
每个分区中有两个角色,类似主从,生产者和消费者只与leader节点交互,leader节点出故障后,会从所有的follower节点中选举出一个新的leader节点继续提供服务。
消息队列两种传递消息的模式,以及优缺点
点对点模式
消息生产者将消息发送到消息队列中,消息消费者从消息队列中取出并且消费数据,消息被消费后,消息队列中不在存储,所有消息消费者不可能接受到已经被消费的消息。 消费者在接收消息后需要向队列应答成功,以便消息队列删除该消息。 类似客服,一个客户打客服电话,同时只能有一个客服人员进行解答。
发布/订阅模式
消息生产者将消息发布到topic中,可以有多个消费者订阅该topic进行消费,达到一对多的效果。 类似报纸,出版社发行报纸后可以有很多人去购买阅读
消费者与消费者组
消费者组
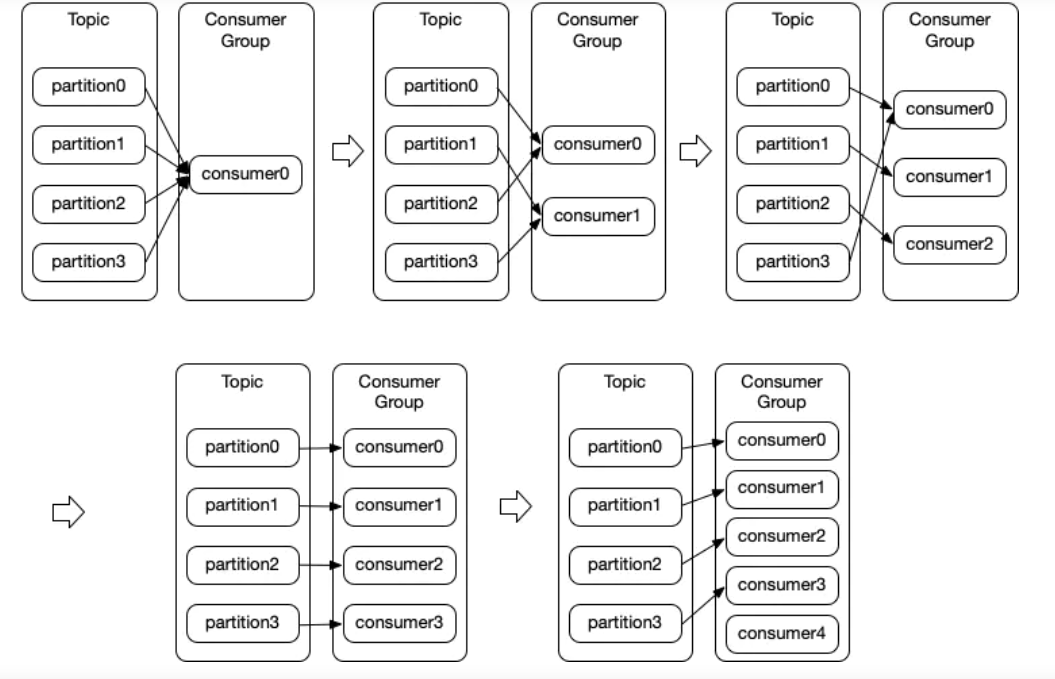
当生产者向 Topic 写入消息的速度超过了消费者(consumer)的处理速度,导致大量的消息在 Kafka 中淤积,此时需要对消费者进行横向伸缩,用多个消费者从同一个主题读取消息,对消息进行分流。
消费者与消费者组的关系
Kafka 的消费者都属于消费者组(consumer group)。一个组中的 consumer 订阅同样的 topic,每个 consumer 接收 topic 一些分区(partition)中的消息。同一个分区不能被一个组中的多个 consumer 消费。换句话说:每一个分区内的消息,只能被同消费组中的一个消费者消费。
消费者组(consumer group) :
当生产者向 Topic 写入消息的速度超过了消费者(consumer)的处理速度,导致大量的消息在 Kafka 中淤积,此时需要对消费者进行横向伸缩,用多个消费者从同一个主题读取消息,对消息进行分流。
Kafka 的消费者都属于消费者组(consumer group)。一个组中的 consumer 订阅同样的 topic,每个 consumer 接收 topic 一些分区(partition)中的消息。同一个分区不能被一个组中的多个 consumer 消费。
一个topic有四个分区,随着消费者组中的消费者数量增加时,该topic分区中数据被读取的情况
acks
这里的acks指的是producer的消息发送确认机制。
ack有三个值可以选择 0,1,-1(all)
ack = 0,就是kafka生产端发送消息之后,不管broker的副本有没有成功收到消息,在producer端都会认为是发送成功了,这种情况提供了最小的延迟,和最弱的持久性,如果在发送途中leader异常,就会造成数据丢失。
ack = 1,是kafka默认的消息发送确认机制,此机制是在producer发送数据成功,并且leader接收成功并确认后就算消息发送成功,但是这种情况如果leader接收成功了,但是follwer未同步时leader异常,就会造成上位的follwer丢失数据,提供了较好的持久性和较低的延迟性。
ack =-1,也可以设置成all,此机制是producer发送成功数据,并且leader接收成功,并且follwer也同步成功之后,producer才会发送下一条数据。
ack
自动提交
最简单的方式是消费者自动提交偏移量。如果 enable.auto.commit 设为 true,那 么每过一定时间间隔,消费者会自动把从 poll() 方法接收到的最大偏移量提交上去。提交时间间隔由 auto.commit.interval.ms 控制,默认是5s。
缺点: 假如在提交时间间隔内发生了分区再均衡(比如topic添加分区,会将消息进行重新分配),会发生消息重新被消费的情况,所以只能通过调小提交时间间隔来更频繁的提交偏移量,但也无法完全避免。
手动提交
同步提交
把 auto.commit.offset 设为false,使用commitSync()方法提交偏移量最简单也最可靠,该方法会提交由 poll()方法返回的最新偏移量,提交成功后马上返回,如果提交失败就抛出异常。需在poll()的所有数据处理完成后再调用。只要没有发生不可恢复的错误,commitSync() 会一直尝试直至提交成功。如果提交 失败会抛出 CommitFailedException 异常。
异步提交
手动提交有一个不足之处,在 broker 对提交请求作出回应之前,应用程序会阻塞,这会影响应用程序的吞吐量。可以使用异步提交的方式,不等待 broker 的响应。 异步提交是不能重试的,因为重试的时候,待提交的位移很可能是一个过期的位移(也就是偏移量值大的有可能会比偏移量值小的先提交)。对于失败或者成功后续的处理,可以在定义的回调函数中进行处理。 方法: consumer.commitAsync()
kafka java api使用
pom.xml
<!-- kafka客户端工具 主要依赖 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
<!-- 工具类 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>
<!-- SLF桥接LOG4J日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.6</version>
</dependency>
<!-- SLOG4J日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
生产者
package producer.one;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.KafkaAdminClient;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class KafkaProducerOne {
private static final String TOPIC_TWO = "topic_two";
public static void main(String[] args) {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
// 指定Kafka集群的地址,可以设置一个或多个,多个使用英文逗号隔开
props.put("bootstrap.servers", "192.168.181.128:9092,192.168.181.129:9092,192.168.181.130:9092");
// 提供了一个常量类,其中有kafka生产者所需要的配置以及说明
// props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.181.128:9092,192.168.181.129:9092,192.168.181.130:9092");
// 0: 如果设置为零,则生产者根本不会等待来自服务器的任何确认。该记录将立即添加到套接字缓冲区并被视为已发送。这种情况下不能保证服务端已经收到记录,retries 配置也不会生效(因为客户端一般不会知道任何失败)
// 1: 这意味着领导者会将记录写入其本地日志,但会在不等待所有追随者的完全确认的情况下做出响应。在这种情况下,如果领导者在确认记录后但在追随者复制它之前立即失败,那么记录将丢失。
// 2: 这意味着领导者将等待完整的同步副本集来确认记录。这保证了只要至少一个同步副本保持活动状态,记录就不会丢失。这是最有力的保证。这相当于 acks=-1 设置。
props.put("acks", "all");
// 与生产者客户端 KafkaProducer 中的 key.serializer 和 value.serializer 参数对应。消费者从 broker 端获取的消息格式都是字节数组(byte[])类型,所以需要执行相应的反序列化操作才能还原成原有的对象格式。
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 手动创建Topic,如果没有手动创建也会自动创建
AdminClient create = KafkaAdminClient.create(props);
// 创建一个拥有两个分区,一个副本的Topic
create.createTopics(Arrays.asList(new NewTopic(TOPIC_TWO, 2, (short) 1)));
create.close();
// 2. 创建一个生产者对象KafkaProducer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
// 3. 调用send发送1-10消息到指定Topic
for (int i = 0; i < 10; ++i) {
try {
// 获取返回值Future,该对象封装了返回值
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>(TOPIC_TWO, null, i + ""));
// 调用一个Future.get()方法等待响应
RecordMetadata record = future.get();
System.out.printf("topic = %s ,partition = %d,offset = %d%n", record.topic(), record.partition(),
record.offset());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
// 5. 关闭生产者
producer.close();
}
}
消费者
package consumer;
import constans.Constans;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerOne {
private static final String TOPIC_TWO = "topic_two";
public static void main(String[] args) {
// 1. 创建用于连接Kafka的Properties配置
Properties props = new Properties();
// 同时提供了一个Kafka消费者的配置常量类
// props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.181.128:9092,192.168.181.129:9092,192.168.181.130:9092");
props.setProperty("bootstrap.servers", "192.168.181.128:9092,192.168.181.129:9092,192.168.181.130:9092");
// 消费者隶属的消费组的名称
props.setProperty("group.id", "topic_two-group_one");
// 是否自动提交 true:是 false:否
props.setProperty("enable.auto.commit", "true");
// 定时提交,自动提交时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2. 创建一个消费者对象KafkaConsumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 3. 订阅指定的Topic,如果参数为空代表取消订阅
consumer.subscribe(Collections.singletonList(TOPIC_TWO));
while(true) {
// 4. 参数毫秒,每多少毫秒从服务器开始拉取数据,
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
records.forEach(record -> {
System.out.printf("topic = %s ,partition = %d,offset = %d, key = %s, value = %s%n", record.topic(), record.partition(),
record.offset(), record.key(), record.value());
});
}
}
}
控制台输出
可以看到该topic中有两个分区,并且不同分区之间数据不一样
topic = topic_two ,partition = 1,offset = 105, key = null, value = 0
topic = topic_two ,partition = 0,offset = 105, key = null, value = 1
topic = topic_two ,partition = 1,offset = 106, key = null, value = 2
topic = topic_two ,partition = 1,offset = 107, key = null, value = 4
topic = topic_two ,partition = 1,offset = 108, key = null, value = 6
topic = topic_two ,partition = 0,offset = 106, key = null, value = 3
topic = topic_two ,partition = 0,offset = 107, key = null, value = 5
topic = topic_two ,partition = 1,offset = 109, key = null, value = 8
topic = topic_two ,partition = 0,offset = 108, key = null, value = 7
topic = topic_two ,partition = 0,offset = 109, key = null, value = 9
在 topic: topic_two 消费者组中再添加一个消费者后打印
两个消费者设置相同的group.id即可
消费者1
topic = topic_two ,partition = 0,offset = 110, key = null, value = 0
topic = topic_two ,partition = 0,offset = 111, key = null, value = 2
topic = topic_two ,partition = 0,offset = 112, key = null, value = 4
topic = topic_two ,partition = 0,offset = 113, key = null, value = 6
topic = topic_two ,partition = 0,offset = 114, key = null, value = 8
消费者2
topic = topic_two ,partition = 1,offset = 110, key = null, value = 1
topic = topic_two ,partition = 1,offset = 111, key = null, value = 3
topic = topic_two ,partition = 1,offset = 112, key = null, value = 5
topic = topic_two ,partition = 1,offset = 113, key = null, value = 7
topic = topic_two ,partition = 1,offset = 114, key = null, value = 9
可以看到分片中的数据被均匀的分配到了两个消费者中
手动提交
// 同步提交:方法本身是阻塞的,如果没消费一条进行一次位移提交,势必会拉低整体性能。
consumer.commitSync();
// 异步提交:异步提交是不能重试的,因为重试的时候,待提交的位移很可能是一个过期的位移。
consumer.commitAsync();
// 异步提交:回调
consumer.commitAsync(new OffsetCommitCallback() {
// 提交完成时回回调此函数
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception e) {
for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : offsets.entrySet()) {
TopicPartition key = entry.getKey();
OffsetAndMetadata value = entry.getValue();
System.out.println("topic:"+ key.topic()+" partition:"+key.partition() +" offset:"+value.offset() +" metadata:"+value.metadata());
}
if (e != null)
System.out.println("Commit failed for offsets "+ offsets);
}
});
springboot结合Kafka
pom.xml
<!--Spring整合Kafka-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.7.13</version>
</dependency>
yml
server:
port: 8088
spring:
kafka:
# kafka集群地址
bootstrap-servers: '192.168.181.128:9092,192.168.181.129:9092,192.168.181.130:9092'
producer:
acks: all
# 键序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# # 值序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# # 消息重试次数
# retries: 0
consumer:
# 消费者组id
# group-id:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 新增一个消费者组时会从头(第一条消息)开始消费,无论之前是否partition提交过offset
# auto-offset-reset: earliest
# 从最新的消息开始消费
auto-offset-reset: latest
创建topic
package top.taoqz.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.TopicBuilder;
@Configuration
public class KafkaConfig {
@Bean("bootTopic_one")
public NewTopic bootTopicOne() {
return TopicBuilder.name("bootTopic_one")
.partitions(10)
.replicas(1)
.compact()
.build();
}
@Bean("bootTopic_two")
public NewTopic bootTopicTwo() {
return TopicBuilder.name("bootTopic_two")
.partitions(3)
.replicas(1)
.compact()
.build();
}
}
ack配置
package top.taoqz.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ContainerProperties;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
@Component
public class KafkaAckConfig {
private static final Logger log = LoggerFactory.getLogger(KafkaAckConfig.class);
@Value("${spring.kafka.bootstrap-servers}")
private String servers;
private Map<String, Object> consumerProps() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
@Bean("ackContainerFactory")
public ConcurrentKafkaListenerContainerFactory ackContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory(consumerProps()));
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
factory.setConsumerFactory(new DefaultKafkaConsumerFactory(consumerProps()));
return factory;
}
}
生产者
ListenableFuture send = kafkaTemplate.send("bootTopic_one", partition, "myKey", message);
消费者
package top.taoqz.consumer;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.boot.autoconfigure.kafka.ConcurrentKafkaListenerContainerFactoryConfigurer;
import org.springframework.context.annotation.Bean;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.listener.DeadLetterPublishingRecoverer;
import org.springframework.kafka.listener.SeekToCurrentErrorHandler;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
import org.springframework.util.backoff.BackOff;
import org.springframework.util.backoff.FixedBackOff;
@Slf4j
@Component
public class KafkaConsumer {
/**
* 默认自动提交
*
* @param record
*/
@KafkaListener(groupId = "hello1",
topicPartitions = @TopicPartition(
topic = "bootTopic_one", partitions = {"1", "3", "5", "7", "9"}
))
public void processMessage(ConsumerRecord record) {
System.out.println("consumer1:" + record);
}
/**
* 不会自动提交,需手动调用 ack.acknowledge() 方法
*
* @param record
* @param ack
*/
@KafkaListener(topics = "bootTopic_one", groupId = "hello2",
containerFactory = "ackContainerFactory",
topicPartitions = @TopicPartition(
topic = "bootTopic_one", partitions = {"0", "2", "4", "6", "8"}
// topic = "bootTopic_one", partitions = {"5"}
))
public void processMessage2(ConsumerRecord record, Acknowledgment ack) {
System.out.println("consumer2:" + record);
ack.acknowledge();
// ack.nack(60000);
}
// @Autowired
// private KafkaTemplate template;
@Bean
public ConcurrentKafkaListenerContainerFactory<?, ?> kafkaListenerContainerFactory(
ConcurrentKafkaListenerContainerFactoryConfigurer configurer,
ConsumerFactory<Object, Object> kafkaConsumerFactory,
KafkaTemplate<Object, Object> template) {
ConcurrentKafkaListenerContainerFactory<Object, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
configurer.configure(factory, kafkaConsumerFactory);
// 创建 FixedBackOff 对象 设置重试间隔 10秒 次数为 3次
BackOff backOff = new FixedBackOff(5 * 1000L, 3L);
factory.setErrorHandler(new SeekToCurrentErrorHandler(new DeadLetterPublishingRecoverer(template), backOff));
return factory;
}
/**
* 方法抛出异常,经过重试后仍不能消费时进入死信队列
*
* @param record
*/
// @KafkaListener(topics = {"bootTopic_two"}, groupId = "bootTopic_two")
public void processMessageBootTopicTwo(ConsumerRecord record) {
System.out.println("重试。。。");
throw new RuntimeException();
}
/**
* 死信队列
* 死信队列的命名方式: 队列名称 = ".DTL"
*
* @param record
*/
// @KafkaListener(topics = {"bootTopic_two.DLT"}, groupId = "bootTopic_two.DLT")
public void bootTopicTwoDLT(ConsumerRecord record) {
System.out.println("死信队列接收消息:" + record);
}
}
死信+重试
package top.taoqz.consumer;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.annotation.DltHandler;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.RetryableTopic;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.retry.annotation.Backoff;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class KafkaConsumerDeadLetter {
/**
* attempts 最多重试次数(成功+失败的总次数)
*
* @param in
* @param topic
* @param offset
*/
@RetryableTopic(attempts = "3", backoff = @Backoff(delay = 2_000, maxDelay = 10_000, multiplier = 2))
@KafkaListener(id = "bootTopic_two_group", topics = "bootTopic_two")
public void listen(String in, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(KafkaHeaders.OFFSET) long offset) {
log.error("Received: {} from {} @ {}", in, topic, offset);
throw new RuntimeException("failed.......");
}
@DltHandler
public void listenDlt(String in, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(KafkaHeaders.OFFSET) long offset) {
log.error("DLT Received: {} from {} @ {}", in, topic, offset);
}
}